Developing SP2010 custom search solutions can be rewarding. Custom solutions can enhance SharePoint search by giving user’s the ability to search by properties and manipulate the results. However, making custom search solutions that can be used with either MSS or FAST search can be much more complicated. In this post I am going to layout the similarities, differences and problems between both MSS search and FAST search. I am also going to explain problems that currently exist in SP2010 and FAST search and possible remedies.
MSS compared to FAST search
MSS (Microsoft Shared Services) and FAST have much in common. In fact if you have both installed on your farm, then users will not see much difference between SharePoint and FAST search web parts and search centers. The noticeable difference is in the results where FAST results will include a refinement web part that displays counts and thumbnail images of Word and PowerPoint files. Even from an administrative perspective both MSS and FAST support the following:
Service Application Infrastructure
Metadata schema management
Crawl scheduling
Scopes, Best Bets and Synonyms
The biggest differences between SharePoint and FAST is FAST’s more robust ability to crawl millions of documents and better relevance in search results. SharePoint search can efficiently crawl and query up to 100 million documents, whereas, FAST can efficiently do the same up to a 500 million documents.
Another substantial difference is the object model and many other little quirks that you will encounter when developing custom search solutions.
| Supported Syntax | Object Model | |
| MSS | Keyword FullTextSQL | Microsoft.Office.Server.Search |
| FAST | Keyword FQL | Microsoft.Office.Server.Search Microsoft.SharePoint.Search.Extended.Administration |
When developing search solutions that support managed property searching you can use either the KeywordQuery or the FullTextSQLQuery class. The KeywordQuery class now supports the operators (OR,AND,NOT,NEAR) when doing property searching. These type of operators were only available through the FullTextSQLQuery class using SharePoint Search SQL syntax in SP2007. Keyword Query Syntax
In some situations you may want to use the FullTextSQLQuery class which supports other proximity operators and full text operators such as CONTAINS which can be more effective for exact results. In addition, the mapped crawled property does not need to be mapped to the full text index which is required for Keyword property searching. SharePoint Search SQL syntax reference
FAST does not support SharePoint Search SQL queries. Microsoft now recommends you develop all your search solutions using the KeywordQuery class so they can be seamlessly used between both SharePoint and FAST search. However, just like with SharePoint search if you need to create more complex searches in your solution, then you should use FQL (FAST Query Language). The KeywordQuery class exposes the EnableFQL property. By setting this property to true your solution can use FQL which is an ABNF (Augmented Backus-Naur Form) language for more exact searching using managed properties. FQL syntax reference
Below are examples of the same query using SQL, Keyword and FQL Syntax:
| SQL | SELECT Title,Created,Path FROM SCOPE() WHERE (Title = 'Whatever' OR FileExtension = 'PDF') |
| Keyword | title:whatever OR fileextension:PDF |
| FQL | or(title:equals("whatever"),fileextension:equals("PDF")) |
So this is where things start getting different. You will notice that the SQL query includes a SELECT list of properties to retrieve in the results. So how do you tell SharePoint which properties to return with Keyword or FQL syntax? In the code below you will see how using the SelectProperties collection of the KeywordQuery class lets you add the properties you want to return. You can easily add a range of property names.
|
public DataTable Execute(string queryText, try SearchServiceApplicationProxy ssap = using (KeywordQuery query = new KeywordQuery(ssap)) if (selectProperties != null && selectProperties.Count > 0) } rtc = query.Execute(); if (rtc.Count > 0) using (ResultTable relevantResults = rtc[ResultType.RelevantResults]) } } } } return retResults; } |
Notice how you can switch search providers by using the ResultsProvider property. The property is set to the FASTSearch provider, but it can also be set to SharePointSearch or Default. Default will use whatever provider the search service application proxy is configured for. If your query is using FQL syntax you must set the EnableFQL to true. If you don’t and the solution submits a FQL syntax query it will raise an error. A final note about using FQL and FAST search is that the property names must be in lower case. SQL and Keyword search property names are case insensitive, but not FQL. So if you use a property name that is not all lower case, then the code will raise a “Property doesn't exist or is used in a manner inconsistent with schema settings” error.
Both FullTextSQLQuery and the KeywordQuery class’s execute method returns a ResultTableCollection object which you then load the results into a DataTable. Here is the strange part with FAST. It returns a DataTable object where the data columns are read only and all the data column types are strings. This can be a problem if your solution binds directly to the DataTable . For instance if your grid has sorting and the managed property is expected to be a date time value, then the dates are sorted as strings. You can fix this issue by cloning the DataTable, changing the column’s data type and then importing the row.
|
DataTable convertedResults = results.Clone(); foreach (DataColumn dc in convertedResults.Columns) if (selectProperties.ContainsKey(dc.ColumnName)) foreach (DataRow dr in results.Rows) |
Searching Problems
Both SharePoint and FAST have quirky issues when searching decimal type managed properties. SharePoint search has a feature in the schema where you can automatically create new managed properties for newly discovered crawled properties. However, if the crawled property is a decimal, then the crawler does not store the decimal portion of the value from SharePoint. For example, if your value in SharePoint is 10.12345, then the value stored is 10.00000. This basically makes searching for decimal amounts useless. Fortunately, Microsoft will be issuing a hot fix for this in the February 2011 cumulative update. The work around for this is to delete the automatically created managed property and create your own, then do a full crawl.
FAST has similar issues with the decimal type managed properties but more subtle. When using the FQL int or float functions, FAST will only search up to 3 decimal places. Using the example above, if you search for 10.123 you will find your invoice, however if you use 10.12345 it will not. Is this a problem? I am not sure how many people use more than 3 decimal places in SharePoint.
One of the most common ways to search in SharePoint is to find a document based on a text managed property. Unfortunately, SP2010 has made this more complicated. SP2010 search is more scalable than SP2007 and one reason is the new feature of reducing storage space for text type managed properties. When creating a new text managed property you can set the “Reduce storage requirements for text properties by using a hash for comparison” option. If you do not set this option the “=” operator will not work. You can only use the CONTAINS full text predicate function with the FullTextSQLQuery class or the “:” operator with the KeywordQuery class, both of which will return results where the term is located within the text. This does not produce an exact match.
Schema Issues
Both SharePoint and FAST give you access to managed and crawled properties using the object model. You can access SharePoint search schema using the Microsoft.Office.Server.Search.Administration. However, with FAST you must use the Microsoft.SharePoint.Search.Extended.Administration.Schema namespace located in the Microsoft.SharePoint.Search.Extended.Administration.dll. FAST schema administration object model reference
One of the most common errors seen when searching SharePoint is the “Property doesn't exist or is used in a manner inconsistent with schema settings” error. To avoid getting this error in your custom solution you must prevent managed properties from being used that are not “Queryable”. The “Queryable” criteria is different between SharePoint and FAST. With SharePoint search you must use the ManangedProperty.GetDocumentsFound method to determine if any documents in the index are using this managed property. However, with FAST you must check both the ManagedProperty.Queryable and ManagedPropety.SummaryType properties. Queryable must be true and the SummaryType cannot be disabled. Both these options are available when creating a new managed property in FAST.
A convenient features in SharePoint search is the the ability to have your managed properties automatically generated when a new crawled property is discovered during crawling. This eliminates the need to have an administrator set up the crawled property before your solution can start using it. This setting can be set by editing the crawled property category. Unfortunately, setting it in FAST does not work. All your managed properties must be manually created when using FAST.
Best bets for SharePoint search solutions
Microsoft is recommending standardizing on using the KeywordQuery class for custom search solutions to make it easier for your solution to seamlessly use both search technologies. However, there are still many differences between both which require your solution to add logic that depends on which technology you are using. To keep your solution clean and maintainable, I recommend that you develop your own provider based object model to abstract away the differences between SharePoint and FAST search. Your solution would then interact with a standard interface and each one of your custom providers would handle differences in syntax, schema, searching and object model dependencies.
Microsoft has made it easy to use FAST in SP2010, but in order to leverage it you still must have a deeper knowledge.








 Adding properties to search with
Adding properties to search with
 Adding properties to return in your search results
Adding properties to return in your search results
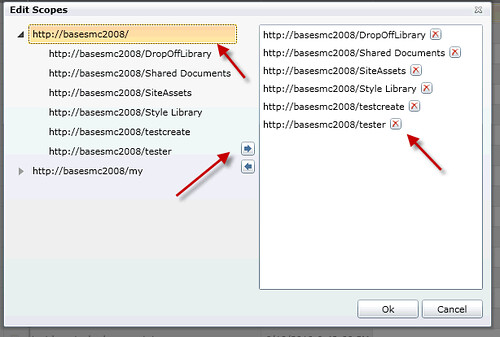
 Limiting the scope of your search
Limiting the scope of your search