I have recently been working on a project where we needed to evaluate the state of an object and depending on the state take certain actions. Seems like a simple coding task to get this done, unless the rules to evaluate state are completely dynamic. An application where rules need to be captured and easily changed typically calls for a rules engine. A rules engine separates business rules from the execution code. Most rules engines require the use of variables along with rules implemented in some framework code. This could be a scripting language or a full fledge programming language like C# or Java. If the rules change usually some code change must take place.
Rules engines are divided into two parts, conditions and actions. Business applications will define conditions and the corresponding actions the application should take given the conditions. The conditions in a rules engine consist of a set of evaluations of the state of an object at any given point of time. I propose that given the capabilities of a search engine it could be used as a rules engine. Conditions in a rules engine can be converted to a query against a particular document (JSON). The query could be stored and used by the rules engine to evaluate the state of a document and then take the associated actions if the document meets the conditions. Leveraging the richness of the query language would increase the capabilities of the rules engine to define very complex rules and possibly make rule processing faster. So what would the required features of a search product be in order for it to function as a rules engine?
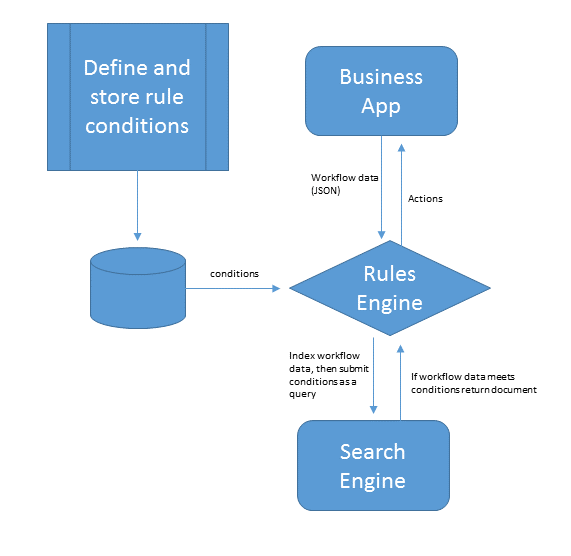
Required Features of a Search Based Rules Engine
Index Any Type of Document
The first feature of a search product to function as a rules engine would be the ability to index any type of document. In this case a document would be any valid JSON document. In addition, since application data can be very dynamic a search product with the ability to query any value of that data without the overhead of having to define the schema of the document would be even better.
A Rich Query Domain Specific Language
Application rules can be very complicated and if you are going to use search as a rules engine then the product must have a strong query DSL (Domain Specific Language). The DSL should support the grouping or chaining of queries together to form a true or false condition. The query DSL should also support the turning off of word breaking of string values. Rules typically require exact matches and some search engines word break by default. Finally the query DSL should have the ability to be easily stored and retrieved. This ability is essential since you will want to capture business rules and translate them to query DSL storing them for later execution.
Near Real-Time Indexing
How fast a document is available to be searched after indexing is the most important feature for a search rules engine. Some applications will have data that is changed and must be evaluated immediately. In this case the search product must support real-time indexing where the document is available within one second. In other cases where the data is relatively stagnant it is possible to have higher index latency.
SharePoint Search , Azure Search and Elasticsearch How Do They Stack Up?
SharePoint Search
Unfortunately, SharePoint Search fails on all three features. SharePoint does not have real-time indexing. There is no ability to programmatically index a document. Secondly it cannot index any type of document. It is limited to whatever IFilters that have been enabled. Finally the query DSL (KQL) is limited. There has been innovation with Delve and the Graph query DSL, however, it is still limited to social and collaboration scenarios.
Azure Search
Azure Search is built on top of Elasticsearch and is strong in all the features except the query DSL. The query DSL remains simple and is geared more towards less robust mobile apps. You can index any type of document however you must define your schema before it can be searched on anything other than it’s ID. You can search on your document within one second of indexing. A great benefit is that all fields are filterable by default, which means they support exact value matching only.
Elasticsearch
ElasticSearch meets all the above feature requirements to be a search rules engine. You can index any document and search on it within one second and not have to define a schema. The ElasticSearch query DSL has an incredible amount of features to support a search rules engine. It has the ability to combine multiple queries into a complex Boolean expression. However, fields are not by default set up to be searched with exact matching. This will require extra index mapping configuration especially if you are wanting to query arrays of child objects. Finally the query DSL is defined in JSON making it easy to construct, store, and retrieve.
What about NoSQL products like DocumentDB?
NoSQL databases are also an ideal technology for implementing a rules engine. These types of databases can handle large complex documents, however the query DSL for these types of databases can vary and you must trade off between read and write optimizations. With Some NoSQL databases you must do some upfront indexing in order for the data to be immediately available for evaluation.
The Future is JSON Documents
It is becoming much easier to ramp up solutions using JSON documents. The richness and flexibility the format offers makes it easy to integrate multiple data flows into your enterprise solutions. This flexibility along with new search technologies can be combined to implement a fairly robust rules engine to drive some of your workflow applications. Search can play significant role in your applications. Search is not just for finding relevant documents but can be used to supplement or even drive application logic.