One of the biggest mysteries in SharePoint 2013 from a developers perspective has been the REST API. The REST API in SharePoint 2013 has had an huge amount of functionality added to it since SharePoint 2010. Developers have been told that the REST API matches almost everything that is exposed in the managed client server object model (CSOM). Yet as developers we know that what is said about a particular API hardly ever matches up with what it actually can do. Sometimes it can do more than what is said about it. Almost always it can do more than what is documented about it. The SharePoint 2013 REST API until recently has not been a focal point for MSDN documentation. This has resulted in many unproductive hours of developer experimentation with the REST API. Many times we don’t even know where to start and just stick with CSOM or JSOM. Unfortunately, even documentation on the capabilities of JSOM versus CSOM is inaccurate. In this blog post I will attempt to give you a simple explanation of how SharePoint 2013 uses a cache of metadata to validate remote API calls. I have received the dreaded “resource not found” or “ type not found in the model” errors too many times when using REST. So in this post I will also introduce you to a new Visual Studio extension that will give you the ability to browse this metadata. I got tired of opening up reflector every time to figure out if something was available in the REST API. So “necessity is the mother of all invention”. The extension exposes all this information in a very user friendly server explorer extension.
You can get the extension here: SPRemoteAPIExplorer
The Mechanics of SharePoint 2013 Remote API Validation
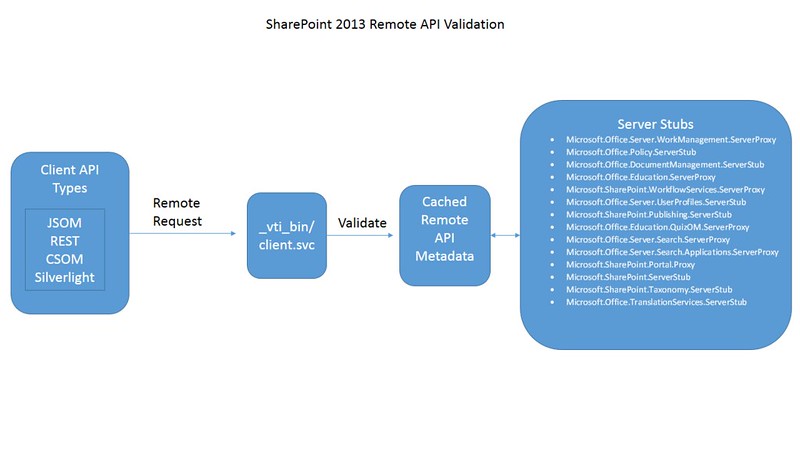
All SharePoint remote requests are sent through the client.svc service. The service will then validate the request against a static in memory cache of metadata. This metadata is supplied by approximately 14 server stub assemblies residing in either the GAC or in the 15/config/bin folder on the SharePoint server. The assemblies are located by SharePoint by examining the xml files contained in the 15/config/clientcallable directory on the SharePoint server. These server stub assembly names emulate the server side object model namespace with either a “ServerProxy” or “ServerStub” appended. Each assembly contains types that inherit from Microsoft.SharePoint.Client.ServerStub. These types expose a GetMethods and a GetProperties method that return objects representing rules on what api can use the server side object and how it should be called. All this information is very useful when building applications that use a remote API.
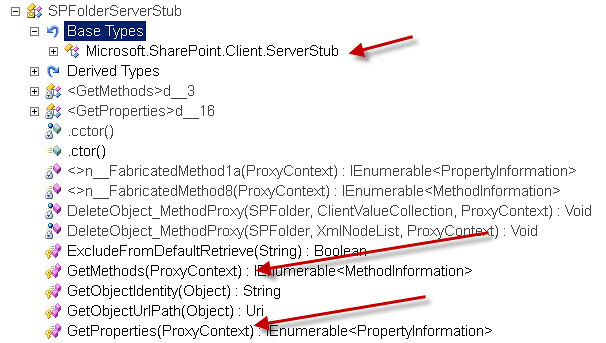
Making the Remote API Metadata Useful with the SPRemoteAPIExplorer Extension
As you can see you would need a reflection tool to examine the types, methods and properties that are available to be called remotely. Why not expose this information in an organized manner within Visual Studio? The SPRemoteAPIExplorer is a Visual Studio (2012 2013) SharePoint server explorer extension. Install the package from the Visual Studio gallery and under any local SharePoint connection you will have an additional node named “Remote API Server Types”. This will contain approximately 361 type nodes representing the server side object model types that can be used through SharePoint’s remote API. Each type if it exposes any methods or properties will have a corresponding methods and properties folder containing the methods and properties.
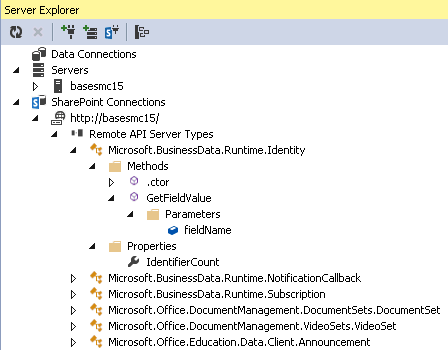
So Where is All the Useful Information?
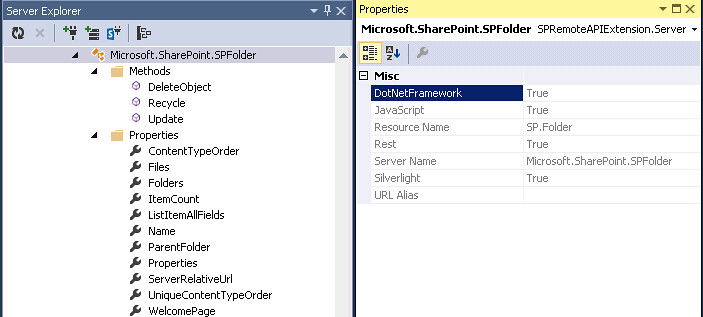
The useful information is contained in the properties panel. If you right click on a type, property, method or parameter you will see all the remote api information in the property grid. The example below shows information for the Microsoft.SharePoint.SPFolder type. For example, this type can be used by the managed CSOM (DotNetFramework), JSOM(JavaScript), REST(Rest) and Sivlerlight CSOM(Silverlight) api. So you should never get a “resource not found” error in your rest call if you are using the corresponding “Resource Name” property either in the URL or the POST content. Also, if there is a URL alias for the type it will be listed here also under the “URL Alias” property.
Information About Methods
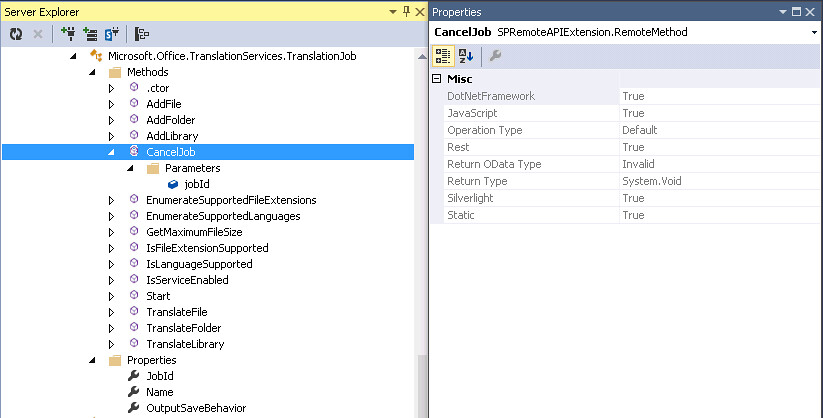
Below is an example of what information you get for methods. In this example the Microsoft.Office.TranslationServices.TranslationJob type exposes 14 methods. It also has a constructor. Please not that some types do have constructors even though some methods may be static. The CancelJob method is available for all the remote api platforms. The “Operation Type” property is an enumeration of either Default or Read. When set to Default the method is for Read and Write operations. If the Operation Type is set to Read the it is for Read only. This enumeration is used in the request process. It appears that the ProxyContext object on the server can be set up to allow only remote requests that request Read operations only. The “Return OData Type” property tells you what OData Type is returned on the method call. In this case it is “Invalid” since the “Return Type” property is void. The following are possible OData return types:
Invalid
Primitive
ComplexType
MultiValue
Entity
Feed
The Primitive type represents scalar or primitive types such as string, int32 etc. You will see a relationship between the “Return OData Type” and the “Return Type” properties. The ComplexType corresponds to a type in the server object model that is not exposed via the EDM entity model or Remote API. These are the types that give most developers a headache. You can use these in REST but you must figure out how to set them up with JSON by looking at the server object model. The MultiValue and Feed types usually represents an array of something. Finally the Entity type represents a type that is defined in the EDM model and Remote API and can be found in the list of types exposed by this extension.
Information About Method Parameters
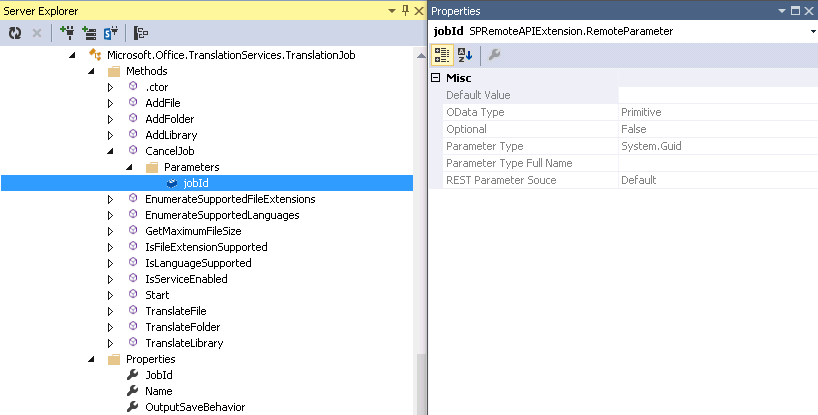
Below is an example of what information is available for method parameters. Methods can have many parameters and cause a lot of development headaches when using REST. The “Default Value” property is the default value that is used when your code does not send a value. The “OData Type” property once again is very useful. Since it is a primitive type you need only to use the name of parameter and the value using JSON. If it were a ComplexType or Entity Type then you would have to include the __metadata property. Now here is something that has driven me nuts with the REST api. In the case where the method is callable from REST but one of the parameters has an Invalid “OData Type” property then it cannot be called through REST. The internal code validates the resource, method and the parameter. Never assume just because the method is callable from REST that it will work. You must also examine all the parameters. An example of this would be the Microsoft.SharePoint.Administration.SPAppCatalog.GetAppInstances method. This method has a web parameter which takes a SPWeb object. These types of parameters are marked as invalid for OData because they are deemed too complex. Hopefully, new methods will be added on the server side to accommodate this by taking a Guid that represents the SPWeb. Finally, the “REST Parameter Source” property is very important. This represents an enumeration defining how the parameter should be passed in a REST call. Once again this has been a huge source of confusion. The following are the valid parameter sources:
Default
Path
QueryString
Body
Default is Body. This means the parameter must be passed in a POST in the content body. The others are self explanatory. However there is some quirkiness. If the parameter “OData Type” is complex then you must look at the underlying server object model type. In the case of the Microsoft.SharePoint.SPAttachmentCollection_Client type and its Add method, it takes a complex type of Microsoft.SharePoint.AttachmentCreationInformation and the “REST Parameter Source” property is set to Path. Unfortunately, this object has two properties FileName and ContentStream. Only FileName can be passed using the path. The ContentStream which represents a stream can only be passed in the content body. So be prudent and check the underlying complex type to make sure all the properties can be passed in the correct manner. Also, when passing parameters using JSON make sure to use the exact parameter name, these appear to be case sensitive.
Information About Properties
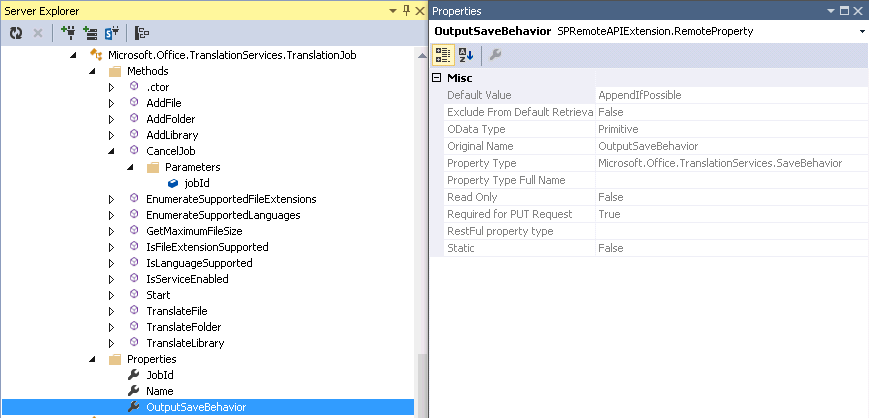
Below is an example of what information is available for properties. One of the more important properties to examine on a remote API property is the “Exclude From Default Retrieval” property. If this is set to true then it will not be returned on an API call. Unfortunately, in the case of REST if it is set to false it does not guarantee it will be returned. If the “OData Type” is set to entity or complexType then it will be deferred. In REST when a property is deferred then only the REST URL to the resource is returned. The “Original Name” property represents the name of the property in the serer object model. Many times these are renamed for URL efficiency. The “Required for PUT Request” is a very strange property. It is used on PUT requests and only applied if the property is “scalar” and not excluded from default retrieval. So if it is set to true but is a entity or complex type then the property probably has no affect when you do not send it on a PUT request.
SPRemoteAPIExplorer Makes REST Development Easier
This extension should make it easier to discover the abilities and use any of the SharePoint remote api’s . In my experience it has saved me trips to the MSDN documentation and numerous hours of trial and error. Even if you are able to get the REST request to pass through to the server, there is no guarantee it will work. There are quirks on the server object model side that will prevent the REST request from working. These are things I hope Microsoft fixes in the future. This extension should give you more time to experiment with the REST api and discover other issues that Microsoft should address. As you play with these you may discover that some may work with SharePoint on-prem but not with SharePoint On-line. While examining server stub framework you can see that the base class Microsoft.SharePoint.Client.ServerStub has the methods IsMethodBlocked, IsSetPropertyBlocked, and IsGetPropertyBlocked. Most all of the derived server stubs make the call back into the base class for these methods. If Microsoft desired to make any of the methods or properties inaccessible, then it would be easy to modify the base or inherited methods and recompile the server stubs.
I will be adding features to this extension in the future and if you have any ideas then just post them in the Q/A section on the Visual Studio Gallery.