I found out yesterday I was awarded MVP for SharePoint Server. Its is great to be rewarded for something you love to do. You cannot keep what you cannot give away. Giving back to the community is an easy thing to do, especially in the MSDN forums. SharePoint is such a product that if you know how something works then you must share it with others, it makes SharePoint better. I work for KnowledgeLake http://www.knowledgelake.com and we offer a great ECM document imaging product. I want to thank KnowledgeLake for giving me the opportunity to develop my knowledge of SharePoint over the last 5 years.
Tuesday, September 8, 2009
Downloading Content From SharePoint (Let me count the ways)
This is a follow up post to the “Uploading Content To SharePoint”. In that post I evaluated the performance and complexity of uploading content to SharePoint with three different methods. In this post I will be doing comparisons for downloading content from SharePoint. Once again there are many ways to get content from SharePoint. When I say content I am focusing on files and metadata. There is an additional way to get a list item using the Lists web service and the GetListItems method; however, this only returns metadata.
| Method | Complexity | Scalability | Metadata | Versions |
| Copy.asmx | 2 | 4 | yes | no |
| WebDav | 5 | 5 | yes* | yes** |
| Rpc | 10 | 10 | yes | yes |
*must be used in conjunction with Lists web service
**must be used in conjunction with Versions web service
Copy Web Service
The copy web service is the easiest to use to get content from SharePoint because it is familiar web service programming and it allows the content and the metadata to be retrieved in one method call. The scalability is not as good as the other methods because it uses the more verbose soap protocol. Finally, one of the biggest disadvantages using the copy web service is the fact that it does not support returning versions of a document. The copy web service was made for migrating content between document libraries and sites within the same site collection not necessarily versions. I did try using the copy web service to retrieve an older version of a document by setting the url argument to the GetItem method using the older version’s url.
The version url looks like this:
http://servername/site/_vti_history/512/documentlibrary/filename.tiff
Unfortunately, when sending in a version url the GetItem method executes successfully but both the metadata and binary are empty.
public static void DownloadDocument()
{
copyservice.Copy c = new copyservice.Copy();
c.Url = "http://basesmcdev2/sites/tester1/_vti_bin/copy.asmx%22;
c.UseDefaultCredentials = true;
byte[] myBinary = new byte[] { };
copyservice.FieldInformation information = new copyservice.FieldInformation();
copyservice.FieldInformation[] info = { information };
string docUrl = "http://basesmcdev2/sites/tester1/Shared%20Documents/+aaa/mama.bmp%22;
uint result = c.GetItem(docUrl, out info, out myBinary);
if(File.Exists("c:\\newfile.bmp")) File.Delete("c:\\newfile.bmp");
using (Stream s = File.Create("c:\\newfile.bmp"))
{
s.Write(myBinary, 0, myBinary.Length);
s.Flush();
}
}
WebDav
Using webdav to download a document is fairly simple if you have the full url of the document. However, if you want to include metadata you must call the GetListItem of the list web service. This becomes tricky when the only piece of information you have is the url. You can use the list web service but you will need to know the name of the list and the id of the item in order to retrieve the metadata. In the end, if you are going to call a SharePoint web service then just call the copy web service and get both the metadata and file in one call.
public static void GetFileWithMetaData(string url)
{
WebClient wc = new WebClient();
wc.UseDefaultCredentials = true;
byte[] response = wc.DownloadData(url);
string returnStr = Encoding.UTF8.GetString(response);
if (File.Exists("c:\\default.txt")) File.Delete("c:\\default.txt");
using (Stream s = File.Create("c:\\detault.txt"))
{
s.Write(response, 0, response.Length);
s.Flush();
}
}
So how does WebDav support versions? You can give the DownLoadData method the url of the version mentioned previously and it will return the binary for that version. So, now the question is how to you obtain the url’s of previous versions? Below is a code snippet that uses the Versions web service to retrieve a particular version’s url for a document for a given file url and version number.
public static string GetVersionUrl(string url, double version)
{
double versionNumeric = 0;
string versionNumber = string.Empty;
string versionUrl = string.Empty;
versionservice.Versions vs = new versionservice.Versions();
vs.Url = "http://basesmcdev2/sites/tester1/_vti_bin/versions.asmx%22;
vs.UseDefaultCredentials = true;
XmlNode versionsNode = vs.GetVersions(url);
if (versionsNode != null)
{
using (StringReader sr = new StringReader(versionsNode.OuterXml))
{
using (XmlTextReader xtr = new XmlTextReader(sr))
{
XElement versionInfo = XElement.Load(xtr);
var versionResults = from r in versionInfo.Elements() where r.Name.LocalName == "result" select r;
foreach (XElement versionElement in versionResults)
{
var versionAttr = (from a in versionElement.Attributes() where a.Name == "version" select a);
versionNumber = versionAttr.First().Value;
versionUrl = versionElement.Attributes("url").First().Value.ToString();
//current version is in the form of "@1.0" and will not pass TryParse
if (versionAttr.Count() > 0 && double.TryParse(versionNumber, out versionNumeric))
if (version == versionNumeric) return versionUrl;
else
if (version == Convert.ToDouble(versionNumber.Substring(1))) return versionUrl;
}
}
}
}
return string.Empty;
}
FrontPage RPC (Remote Procedure Calls)
Most developers are not familiar with frontpage remote procedure calls. However, they are the most efficient and yet the most complex to code against. You could create your own wrapper classes to simplify coding. You must understand the command structure and be able to parse the return html correctly. In the case of downloading a document it is especially complex. You must come up with a way to parse out the returned metadata within the html. Below is an example of a successful return of a “get document” rpc call. Anything below the closing </html> tag is the file.
<html><head><title>vermeer RPC packet</title></head><body><p>method=get document:12.0.0.4518<p>message=successfully retrieved document 'tester4/Code128.tif' from 'tester4/Code128.tif'<p>document=<ul><li>document_name=tester4/Code128.tif<li>meta_info=<ul><li>vti_rtag<li>SWrt:FED298A3-6030-40DA-A984-D0A04A673741@00000000013<li>vti_etag<li>SW"{FED298A3-6030-40DA-A984-D0A04A673741},13"<li>vti_parserversion<li>SR12.0.0.6318<li>vti_modifiedby<li>SRBASESMCDEV2\steve.curran<li>vti_filesize<li>IR3387<li>vti_timecreated<li>TR22 Oct 2008 19:45:25 -0000<li>ContentType<li>SWDocument<li>ContentTypeId<li>SW0x01010087C42E0D80709D4CB61D6558C94571E4<li>vti_title<li>SW<li>statechoice<li>SWstateone<li>vti_lastheight<li>IX2200<li>vti_timelastmodified<li>TR13 Apr 2009 22:04:31 -0000<li>vti_nexttolasttimemodified<li>TR13 Apr 2009 22:02:20 -0000<li>vti_candeleteversion<li>BRtrue<li>vti_canmaybeedit<li>BXtrue<li>vti_backlinkinfo<li>VXLists/threeStateTasks/3_.000 Lists/threeStateTasks/4_.000<li>myreq<li>SWnbnbvnbv<li>vti_author<li>SRBASESMCDEV2\steve.curran<li>vti_lastwidth<li>IX1696<li>vti_sourcecontrolversion<li>SRV1.0<li>vti_sourcecontrolcookie<li>SRfp_internal<li>vti_level<li>IR1</ul></ul></body></html>
Finally, below is an example on how to call the “get document” rpc method. You must work with the returned byte array and copy the section which represents the file to another byte array. This method supports retrieving older versions. Just pass in the version number, zero would represent the current version. The fileUrl argument represents document library name plus the file name. For example, “Shared Documents/FileName.tiff”.
public static void DownloadDocumentRPC(string fileUrl, int version)
{
string method = "get document: 12.0.0.4518";
string serviceName = "http://basesmcdev2/sites/tester1/_vti_bin/_vti_aut/author.dll";
string verstr = version > 0 ? "V" + version.ToString() : string.Empty;
string document = fileUrl;
byte[] data;
string returnStr = string.Empty;
byte[] fileBytes = null;
string fpRPCCallStr = "method={0}&service_name={1}&document_name={2}&doc_version={3}&get_option={4}&timeout=0";
method = HttpUtility.UrlEncode(method);
fpRPCCallStr = String.Format(fpRPCCallStr, method, serviceName, document, verstr, "none");
try
{
//add line feed character to delimit end of command
byte[] fpRPCCall = System.Text.Encoding.UTF8.GetBytes(fpRPCCallStr + "\n");
data = new byte[fpRPCCall.Length];
fpRPCCall.CopyTo(data, 0);
HttpWebRequest wReq = WebRequest.Create(serviceName) as HttpWebRequest;
wReq.Credentials = System.Net.CredentialCache.DefaultCredentials;
wReq.Method = "POST";
wReq.ContentType = "application/x-vermeer-urlencoded";
wReq.Headers.Add("X-Vermeer-Content-Type", "application/x-vermeer-urlencoded");
wReq.ContentLength = fpRPCCall.Length;
using (Stream requestStream = wReq.GetRequestStream())
{
requestStream.Write(fpRPCCall, 0, fpRPCCall.Length);
int chunkSize = 2097152;
//Now get the response from the server
WebResponse response = wReq.GetResponse();
int lastBytesRead, totalBytesRead;
long contentLength = response.ContentLength;
bool noLength = false;
if (contentLength == -1)
{
noLength = true;
contentLength = chunkSize;
}
byte[] returnBuffer = new byte[(int)contentLength];
using (Stream responseStream = response.GetResponseStream())
{
totalBytesRead = 0;
do
{
lastBytesRead =
responseStream.Read(returnBuffer, totalBytesRead, ((int)contentLength) - totalBytesRead);
totalBytesRead += lastBytesRead;
if (noLength && (totalBytesRead == contentLength))
{
contentLength += chunkSize;
byte[] buffer2 = new byte[(int)contentLength];
Buffer.BlockCopy(returnBuffer, 0, buffer2, 0, totalBytesRead);
returnBuffer = buffer2;
}
}
while (lastBytesRead != 0);
}
if (noLength)
{
byte[] buffer3 = new byte[totalBytesRead];
Buffer.BlockCopy(returnBuffer, 0, buffer3, 0, totalBytesRead);
returnBuffer = buffer3;
}
returnStr = Encoding.UTF8.GetString(returnBuffer);
//get begining of file bytes
int startpos = returnStr.IndexOf("</html>") + 8;
using (MemoryStream ms =
new MemoryStream(returnBuffer, startpos, returnBuffer.Length - startpos))
fileBytes = ms.ToArray();
if (File.Exists("c:\\newfile.bmp")) File.Delete("c:\\newfile.bmp");
using (Stream s = File.Create("c:\\newfile.bmp"))
{
s.Write(fileBytes, 0, fileBytes.Length);
s.Flush();
}
}
}
catch (Exception ex)
{
//error handling
}
}
Once again I hope this comparison of the different methods of downloading content from SharePoint will help you plan your next application’s SharePoint integration. Knowing the different methods will prevent you from having write your own web service. Ultimately, taking advantage of SharePoint “out of the box” tools will make your applications easier to install, configure and maintain.
Uploading Content Into SharePoint (Let me count the ways)
Many developers new to SharePoint want to know how to get content into SharePoint from another application. This application is usually a remote application either running in a asp.net application or a desktop application. The developers may be familiar with the SharePoint object model and how to use it to put content into SharePoint. However, when it comes to doing this remotely there seems to be a lot of confusion. This confusion is brought on by the fact that there are numerous out of the box ways of doing this. You can put content into SharePoint by using web services, WebDav or frontpage remote procedure calls. The problem arises when developers chose a method and find out that certain methods don’t support certain functions that you would normally see either from the SharePoint UI or from the SharePoint object model. This article will give you a brief description of the methods available for remotely putting content into SharePoint and compare the methods based on certain factors you should be aware of as a SharePoint developer. These factors include complexity, folder creation, scalability and indexing. Complexity and scalability are rated on a scale of 1 through 10.
| Method | Complexity | Scalability | Indexing | Folder Creation |
| Copy.asmx | 5 | 4 | yes | yes* |
| WebDav | 2 | 5 | yes* | yes* |
| Rpc | 10 | 10 | yes | yes |
* must be used in conjunction with Lists.asmx web service
Copy Web Service
To create content remotely the copy web service is probably your best bet. The copy web service enables you to create new documents and send the metadata for indexing in one call. This makes the web service more scalable. Many times users want to create a new folder to store their documents. Unfortunately, the copy web service does not have a method for creating a folder. The following is a code snippet for creating new content in SharePoint via the copy webs service:
public static void CreateNewDocumentWithCopyService(string fileName)
{
copyservice.Copy c = new copyservice.Copy();
c.Url = "http://servername/sitename/_vti_bin/copy.asmx";
c.UseDefaultCredentials = true;
byte[] myBinary = File.ReadAllBytes(fileName);
string destination = http://servername/sitename/doclibrary/ + Path.GetFileName(fileName);
string[] destinationUrl = { destination };
copyservice.FieldInformation info1 = new copyservice.FieldInformation();
info1.DisplayName = "Title";
info1.InternalName = "Title";
info1.Type = copyservice.FieldType.Text;
info1.Value = "new title";
copyservice.FieldInformation info2 = new copyservice.FieldInformation();
info2.DisplayName = "Modified By";
info2.InternalName = "Editor";
info2.Type = copyservice.FieldType.User;
info2.Value = "-1;#servername\\testmoss";
copyservice.FieldInformation[] info = { info1, info2 };
copyservice.CopyResult resultTest = new copyservice.CopyResult();
copyservice.CopyResult[] result = { resultTest };
try
{
//When creating new content use the same URL in the SourceURI as in the Destination URL argument
c.CopyIntoItems(destination, destinationUrl, info, myBinary, out result);
}
catch (Exception ex)
{
}
}
The benefits of using the copy web service is that it is simple to code against. Most developers are familiar with the web service programming. Also the copy web service supports creating content and metadata in one call thus not creating multiple versions. Unfortunately, this method suffers from one problem and that is the use of byte arrays. If you plan on uploading large files lets say in excess of 2mb, then chances are you will receive sporadic “out of memory” errors. It may not happen on your development server but may happen on your production server. This is because the windows OS needs to allocate byte arrays with contiguous memory. If the server’s memory is fragmented (has a lot of available memory but not much contiguous memory) then you will receive this error. Thus, the copy web service is not very scalable. Finally, web services tend to be verbose given their soap protocol and the marshalling from string to native types makes them slower than other methods.
WebDav
Most developers are familiar with WebDav because it is used to display document libraries in Windows Explorer. Here the familiar dragging and dropping of files into SharePoint can be accomplished. You can accomplish the same thing by using the System.Net.WebClient class as follows:
public static void UploadFile(string fileName, string destination)
{
WebClient wc = new WebClient();
wc.UseDefaultCredentials = true;
byte[] response = wc.UploadFile(destination + Path.GetFileName(fileName) , "PUT", fileName);
}
Ok this seems simple enough. As you can see it is not as complex as using the Copy web service. However, it does not support sending any metadata long with the file content. This can be a major problem if the document library has multiple content types, so the new file will be put into the document library with the default content type. Another big issue is if the default content type has required fields. The file will remain checked out until the fields are populated. This prevents other users from seeing the document or from being returned in any searches. It is a great solution if you are just bulk migrating data from an external data store to SharePoint. You more than likely will have to do extra work afterwards. Adding metadata after uploading will also cause the creation of extra versions of the document being created unnecessarily. The fact that it does not use the soap protocol but straight http makes it more scalable than the copy web service. Unfortunately, it still suffers from the fact that it uses a byte array to upload the file. So sooner or later you will run into “out of memory “ exceptions. So how can I create a folder before using WebDav? You can use the lists web service to accomplish this:
public static XmlNode UpdateListItemCreateFolder(string docLibraryName, string folderName)
{
listservice.Lists listProxy = new listservice.Lists();
string xmlFolder = "<Batch OnError='Continue'><Method ID='1' Cmd='New'><Field Name='ID'>New</Field><Field Name='FSObjType'>1</Field><Field Name='BaseName'>” + folderName + “</Field></Method></Batch>";
XmlDocument doc = new XmlDocument();
doc.LoadXml(xmlFolder);
XmlNode batchNode = doc.SelectSingleNode("//Batch");
listProxy.Url = "http://servername/sitename/_vti_bin/lists.asmx";
listProxy.UseDefaultCredentials = true;
XmlNode resultNode = listProxy.UpdateListItems(docLibraryName, batchNode);
return resultNode;
}
FrontPage RPC (Remote Procedure Calls)
Most developers are not familiar with RPC and what it can do. The complexity of coding RPC is high due to the fact that construction of commands and the interpreting of responses can be tedious and error prone. However this method proves to be the most scalable and the fastest. It also supports sending both the content and the metadata in one call. RPC has numerous commands including one for creating folders and it supports the use of streams rather than a byte array. Below is sample code to create a new document in SharePoint using RPC with a stream.
public static void CreateDocumentRPC(string name, string docLib, string title, bool overWrite, Stream fileBinary)
{
string method = "put document: 12.0.0.4518";
string serviceName = "http://servername/sitename/_vti_bin/_vti_aut/author.dll";
string document = docLib + "/" + name;
string metaInfo = string.Empty;
string putOption = overWrite ? "overwrite" : "edit";
string keepCheckedOutOption = "false";
string comment = string.Empty;
string returnStr = string.Empty;
byte[] data;
string returnError = string.Empty;
string fpRPCCallStr = "method={0}&service_name={1}&document=[document_name={2};meta_info=[{3}]]&put_option={4}&comment={5}&keep_checked_out={6}";
method = HttpUtility.UrlEncode(method);
putOption = HttpUtility.UrlEncode(putOption);
metaInfo = "vti_title;SW|" + title;
fpRPCCallStr = String.Format(fpRPCCallStr, method, serviceName, document, metaInfo, putOption, comment, keepCheckedOutOption);
try
{
//add line feed character to delimit end of command
byte[] fpRPCCall = System.Text.Encoding.UTF8.GetBytes(fpRPCCallStr + "\n");
data = new byte[fpRPCCall.Length];
fpRPCCall.CopyTo(data, 0);
HttpWebRequest wReq = WebRequest.Create(serviceName) as HttpWebRequest;
wReq.Credentials = System.Net.CredentialCache.DefaultCredentials;
wReq.Method = "POST";
wReq.ContentType = "application/x-vermeer-urlencoded";
wReq.Headers.Add("X-Vermeer-Content-Type", "application/x-vermeer-urlencoded");
wReq.ContentLength = fpRPCCall.Length + fileBinary.Length;
using (Stream requestStream = wReq.GetRequestStream())
{
requestStream.Write(fpRPCCall, 0, fpRPCCall.Length);
byte[] tmpData = null;
int bytesRead = 0;
int chunkSize = 2097152;
int tailSize;
int chunkNum = Math.DivRem((int)fileBinary.Length, chunkSize, out tailSize);
//chunk the binary directly from the stream to buffer.
for (int i = 0; i < chunkNum; i++)
{
data = new byte[chunkSize];
bytesRead = fileBinary.Read(tmpData, 0, chunkSize);
requestStream.Write(data, 0, chunkSize);
}
//send the remainde if any.
if (tailSize > 0)
{
data = new byte[tailSize];
bytesRead = fileBinary.Read(data, 0, tailSize);
requestStream.Write(data, 0, tailSize);
}
//Now get the response from the server
WebResponse response = wReq.GetResponse();
int num2,num3;
long contentLength = response.ContentLength;
bool noLength = false;
if (contentLength == -1)
{
noLength = true;
contentLength = chunkSize;
}
byte[] returnBuffer = new byte[(int) contentLength];
using (Stream responseStream = response.GetResponseStream())
{
num3 = 0;
do
{
num2 = responseStream.Read(returnBuffer, num3, ((int) contentLength) - num3);
num3 += num2;
if (noLength && (num3 == contentLength))
{
contentLength += chunkSize;
byte[] buffer2 = new byte[(int) contentLength];
Buffer.BlockCopy(returnBuffer, 0, buffer2, 0, num3);
returnBuffer = buffer2;
}
}
while (num2 != 0);
}
if (noLength)
{
byte[] buffer3 = new byte[num3];
Buffer.BlockCopy(returnBuffer, 0, buffer3, 0, num3);
returnBuffer = buffer3;
}
returnStr = Encoding.UTF8.GetString(returnBuffer);
}
}
catch (Exception ex)
{
//error handling
}
}
As you can see the complexity of coding against rpc can be daunting. You can refactor this code into something much more reusable. Parsing of the return response can be a bit strange also. Below is an example of a successful document creation response from the SharePoint server:
<html><head><title>vermeer RPC packet</title></head>
<body>
<p>method=put document:12.0.0.4518
<p>message=successfully put document 'tester2/crpc.png' as 'tester2/crpc.png'
<p>document=
<ul>
<li>document_name=tester2/crpc.png
<li>meta_info=
<ul>
<li>vti_rtag
<li>SW|rt:61935CFA-736B-4311-97AA-E745777CC94A@00000000001
<li>vti_etag
<li>SW|"{61935CFA-736B-4311-97AA-E745777CC94A},1"
<li>vti_filesize
<li>IR|1295
<li>vti_parserversion
<li>SR|12.0.0.6318
<li>vti_modifiedby
<li>SR|BASESMCDEV2\test.moss
<li>vti_timecreated
<li>TR|19 May 2009 17:28:35 -0000
<li>vti_title
<li>SW|wackout
<li>vti_lastheight
<li>IX|78
<li>ContentTypeId
<li>SW|0x010100B1C4E676904AB94BA76515774B23E02D
<li>vti_timelastmodified
<li>TR|19 May 2009 17:28:35 -0000
<li>vti_lastwidth
<li>IX|411
<li>vti_author
<li>SR|BASESMCDEV2\test.moss
<li>vti_sourcecontrolversion
<li>SR|V1.0
<li>vti_sourcecontrolcookie
<li>SR|fp_internal
</ul>
</ul>
</body>
</html>
If there is not substring of “osstatus” or “Windows SharePoint Services Error” then it is a success.
I hope this helps in your evaluation of different ways you can upload data to SharePoint. There are many things to consider when selecting which method to use. High on your priority list should be speed, scalability and the ability to send metadata. Sometimes the method that looks the hardest can be the best choice and it is up to you as a developer to abstract away the complexity.
Unable to delete unmapped crawled properties in SharePoint Search
Technorati Tags: WSS MOSS Search
One of the most convenient features of SharePoint Search is its ability to automatically discover crawled properties and create new managed properties. This is good because as a SharePoint administrator I don't want to have to take requests from users to set up new managed properties to search on. So basically whenever an incremental crawl occurs and the crawler discovers a new SharePoint column it will create a new crawled property and automatically create a new managed property to search against. The only unfortunate problem is that the crawler creates the new managed property with a name predicated with "ows". This is not very friendly but it is standard way for users to use the property in a keyword search, for example owsDocumentName:salaries.
This automatic managed property creation can be set in Shared Services Administration:SharedServices> Search Settings > Crawled Property Categories > Edit Category.
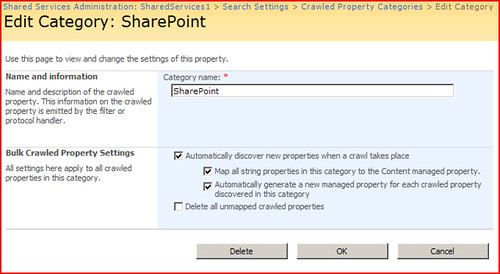
The "Automatically generate a new managed property for each crawled property discovered in this category" option is not checked by default. So many times clients set up their metadata and upload documents without turning this on. Many clients do want to go back and have to set up all the managed properties. So one option is to check the "Delete all unmapped crawled properties" option and click OK. This is supposed to delete all the crawled properties that are not mapped to any managed properties. After this you can do another full crawl and the crawler will rediscover the crawled properties that were deleted and generate new managed properties. Very nice. Unfortunately, this does not work for all unmapped crawled properties. I noticed there were a lot of unmapped crawled properties that were not being deleted. For instance, ows_baseName(Text). According to Microsoft only unmapped crawled properties will be deleted. You can verify this by examining the dbo.proc_MSS_DeleteCrawledPropertiesUnmappedForCategory stored procedure located in the SharedServices database.
So what is the deal here. Examining the managed properties stored in the SharedServices database in the MSSManagedProperties table, I can see a lot of managed properties that have very long PID values such as 214741802 that have their Hidden column set to true. The ows_baseName crawled property is mapped to one of these hidden managed properties called "TempTitle" and thus it could not be deleted. The SharePoint UI will not show these hidden managed properties. Why? All I know is that when I want to delete all unmapped crawled properties it should do so. The UI should show these. Apparently, Microsoft does not want users changing the mappings.
Below is a list of these hidden managed properties. Some of them look interesting. For instance, CrawlUrl or SiteContainer. I tried using some of these in a fulltextSql query but the search engine threw a "Property does not exist error". Really?
2147418028 AnchorLink
2147418033 BaseHref
2147418035 ChangeID
2147418036 CrawlObjectID
2147418090 CrawlUrl
2147418034 CRC
2147450879 DefaultProperties
2147418016 DirLink
2147418021 DirLinkSecurityUpdate
2147418020 DirLinkWithTime
2147418026 EndAnchor
2147418022 FollowAll
2147418023 FollowNone
2147418037 IndexRare
2147418039 LinkHRef
2147418040 LinkOfficeChild
2147418041 LinkOfficeChildList
2147418024 NormalizedForwardURL
2147418025 NormalizedURL
2147418042 PluggableSecurityBlob
2147418089 PluggableSecurityTrimmerId
2147418019 RedirectedURL
2147418018 Robots
2147418080 Scope
2147418027 SecurityBlob
2147418031 SecurityProvider
2147418038 SiteContainer
2147418091 Summary Description
2147418032 TempTitle
2147418029 URLAnchor
Advanced Search retreats
In software development one of the key rules is not to take functionality away from users. However, if you do then you should document the fact. The new infrastructure update removes the "Contains" and "Does not contain" operators from the Advanced Search Box webpart. This is probably due to the fact that the webpart uses the "Like" operator instead of using the CONTAINS fulltext predicate in the fulltext sql it generates. The "Like" operator is very slow, so in large deployments searches like these could slow the server down. The question here is why not just use the CONTAINS predicate and not remove the functionality from the webpart?
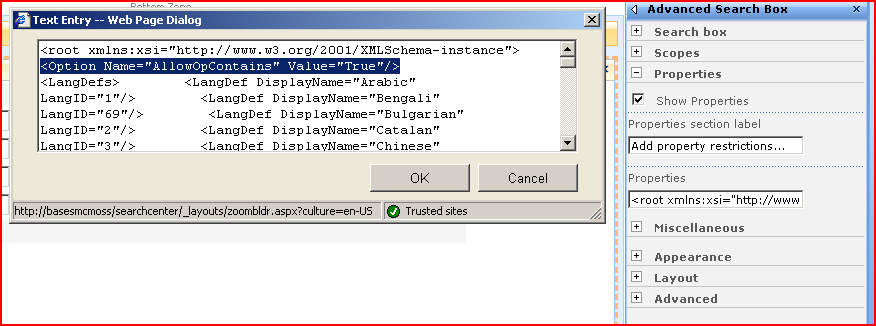
To enable "Contains" you need to edit the "Advanced Search Box" webpart on the Advanced.aspx page. Under the "properties" section of webpart's toolbox click on the button next to the "Properties" text box. This will display a "Text Entry-Web Page Dialog".
At the very top of this xml you will see:
<Option Name="AllowOpContains" Value="False"/>
Change the "Value" attribute to True and save your changes. The "Contains" and "Does Not Contains" should now show up.
SPWeb.ProcessBatchData. A list is a list is a list?
Technorati Tags: SharePoint Development,WSS
There is a lot of material on the Internet about the Microsoft.SharePoint.SPWeb.ProcessBatchData method. It is a great method for processing a lot of commands against a SPList without having to open a SPListItemCollection and pay the penalty of slow performance if the list contains a substantial amount of items. The ProcessBatchData method seems to be used only by the Microsoft.SharePoint.SoapServer namespace (stssoap.dll) which is the assembly that implements the basic SharePoint webservices. For example, the lists webservice uses ProcessBatchData when processing requests to the UpdateListItems method. The UpdateListItems and the ProcessBatchData methods take the "Windows SharePoint RPC Protocol" formatted caml batch commands (http://msdn2.microsoft.com/en-us/library/ms448359.aspx). The point of this article is to clear up some confusion about the actual syntax of this caml and one of the undocumented syntax differences depending on what derived type of SPList you are operating against.
Calling UpdateListItems or ProcessBatchData?
The main focus is to delete a particular item in a list. I have seen many examples of the caml that is needed to accomplish this with the ProcessBatchData method.
Example One (Deleting a file from a SharePoint List) using ProcessBatchData
<?xml version="1.0" encoding="UTF-8"?>
<Batch>
<Method>
<SetList Scope="Request">3010913d-9373-44ec-a799-0bf564cb0d66</SetList>
<SetVar Name="Cmd">DELETE</SetVar>
<SetVar Name="ID">1</SetVar>
</Method>
</Batch>
The above will delete a list item from a standard SharePoint list not a document library. You need to supply the guid of the SPList and the ID property of the SPListItem. Unfortunately this does not work with a document library. If you try using this with a document library you will get "The file name you specified could not be used. It may be the name of an existing file or directory, or you may not have permission to access the file."
Example Two (Deleting a file from a SharePoint Document Library) using ProcessBatchData
<Batch>
<Method>
<SetList Scope="Request">3010913d-9373-44ec-a799-0bf564cb0d66</SetList>
<SetVar Name="Cmd">DELETE</SetVar>
<SetVar Name="ID">1</SetVar>
<SetVar Name="owsfileref">sites/tester1/myfile.bmp</SetVar>
</Method>
</Batch>
The above will delete a list item from a SharePoint document library. You do not need to supply the ID property of the SPListItem but you must supply the item's "Url Path" field for the "owsfileref" variable. The internal name for the "Url Path" field is "FileRef". The ID variable in the caml is ignored and is basically used to number separate commands.
Example Three (Deleting a file from a SharePoint Document Library) using UpdateListItems
<?xml version="1.0" encoding="UTF-8"?>
<Batch>
<Method ID='1' Cmd='Delete'>
<Field Name='ID'>1</Field>
<Field Name='FileRef'>http://basesmcdev/sites/tester1/myfile.bmp</Field>
</Method>
</Batch>
Example three shows the caml to use when using the lists webservice. Yes it is different syntax. It uses the "Field" element instead of the "SetVar" element. Why? Not sure. This caml gets translated by the Microsoft.SharePoint.SoapServer.ListDataImpl.ConstructCaml method into the caml listed in example two and then passed into the ProcessBatchData method.
In summary the Windows SharePoint RPC protocol caml is not documented very well,there are two syntaxes and special variable names that no one knows about like "owsfileref". The good news is that through trial and error (Thomas Edison) you can figure out what works and what does not. Good experimenting.
Check Outs Gone Crazy
It seems to be easy to have a lot of documents checked out in SharePoint 2007, yet nobody knows about them except the person who uploaded the document. SharePoint 2007 lets you upload documents first and then index them later. As you know indexing a document is pretty important if you want to find it. So many times columns in content types will be required. However, SharePoint 2007 gives you so many ways of putting documents into it without setting these required columns. You can upload a document through the UI and then cancel when presented with the EditForm.aspx. Second, you can drag documents from a folder to a webfolder using Windows Explorer without setting the required columns. Finally, you can send documents to SharePoint 2007 using the copy.asmx webs service or use front page extensions rpc calls without setting the required columns.
So what happens to these documents? The required columns have not been populated and the documents probably should not be in SharePoint right? Well they are all checked out to the user that uploaded them. The best part is that user is the only one that can see them, not even a site administrator can see them. You cannot even see them in the object model where you would expect. The documents are in limbo. As a farm or site administrator you might want to know about these documents so you can rectify their state. The SharePoint object model provides a way for you to obtain these documents and do something with them. You can use the SPDocumentLibrary class' CheckeOutDocuments property to get a collection of SPCheckedOutFile objects. SPCheckedOutFile object gives you the ListItemId property which enables you to get the SPListItem object so you can create a report or send an email notification notifying users that these documents need there required columns populated. Alternatively, if you have non-responsive users you can override the checkout and do what you want even check them in without setting the required columns. I don't recommend this since the required properties are there for a reason. The code below gives you an example of how you can use this collection and the SPCheckedOutFile class to accomplish some management of this type of document in your SharePoint repository.
SPListItem docItem = null;
using (SPSite site = new SPSite("http://basesmcdev/sitedirectory/tester1"))
{
using (SPWeb web = site.OpenWeb())
{
SPDocumentLibrary docLib = (SPDocumentLibrary)web.Lists["mosstestsearch"];
foreach (SPCheckedOutFile scf in docLib.CheckedOutFiles)
{
scf.TakeOverCheckOut();
docItem = docLib.GetItemById(scf.ListItemId);
docItem.File.CheckIn(string.Empty);
docItem.File.Update();
}
}
Office 2003 files are second class citizens in SharePoint 2007
Technorati Tags: MOSS WSS Office Document Management
There are many ways to upload files to SharePoint 2007 and they all seem to work well. Unless your using Office 2003 or later.
Uploading files to SharePoint can be done many ways including the upload page, front page extensions remote procedure calls and webdav using Windows Explorer. Of course Microsoft Office uses its own proprietary ways which may involve a combination of webservice and rpc calls depending on what version of Office you are using. Many companies have upgraded to SharePoint 2007 and Office 2007, however; many older Office version files still exist. Companies are putting older Office documents in SharePoint 2007 without converting to Office 2007 format. This seems to be reasonable, until you need to view and edit the document's properties. The catch is the process of "property demotion". SharePoint has a process of property "promotion" and "demotion". When you upload a document and its properties then a document's properties get "promoted" to the matching SharePoint columns. Opening the document from SharePoint then demotes SharePoint properties to the matching document's properties so they can be viewed in the native application. SharePoint 2007 seems to have a problem with the demotion process for Office 2003 documents.
The main problem is using front page remote procedure call "put document". This method makes a direct call to the author.dll uploading the file binary and the corresponding properties you wish to populate. However, uploading Office 2003 files using this method causes an error on SharePoint 2007. After uploading a file you can examine the metadata that is generated for the document in the "AllDocs" table in the corresponding content database in sql server. Below is an example of what is generated in the metaInfo column of the table when you upload a file.
Subject:SW|
vti_error0:SX|Could not process the file mosstestsearch/test.doc as a Microsoft Office document.
vti_parserversion:SR|12.0.0.6219
Keywords:SW|
vti_cachedcustomprops:VX|Subject Keywords _Author _Category _Comments
vti_modifiedby:SR|BASESMCDEV\\steve.curran
vti_title:SW|foreign
ContentType:SW|Document
ContentTypeId:SW|0x01010017483E443739384889CC3E4B64BC3B6B
_Author:SW|joe.smith
_Category:SW|
vti_error:IX|1
_Comments:SW|
vti_author:SR|BASESMCDEV\\steve.curran
testcol:SR|STUFF
You can see when uploading Office 2003 files SharePoint adds a metadata error entry "vti_error0" stating "Could not process the file as a Microsoft Office document". Hmmm. I do believe this is an office document, just not an Office 2007 document. The document's properties are promoted correctly because I can go into the SharePoint UI and view the properties. For instance, vti_title maps to the title property and testcol maps to the testcol property. Unfortunately, if I open this document in Office 2007 none of the properties are visible. So why are these properties not getting demoted correctly? The key here seems to lie with the "vti_cachedcustomprops" property. You can see this is a space delimited list of property names. Apparently, this is what Office 2007 uses to read properties from Office 2003 documents when opening them from SharePoint. I tested this by editing the properties in the SharePoint UI which resulted in the following metadata being inserted into the metaInfo column of the AllDocs table.
vti_lmt:SW|Tue, 26 Feb 2008 19:36:47 GMT
vti_parserversion:SR|12.0.0.6219
_Category:SW|
vti_author:SR|BASESMCDEV\\steve.curran
vti_approvallevel:SR|
vti_categories:VW|
vti_assignedto:SR|
Keywords:SW|
vti_cachedcustomprops:VX|Subject _Category testcol _Comments vti_approvallevel vti_categories vti_assignedto Keywords vti_title _Author
vti_modifiedby:SR|BASESMCDEV\\steve.curran
vti_title:SR|foreign
ContentType:SW|Document
ContentTypeId:SW|0x01010017483E443739384889CC3E4B64BC3B6B
vti_lat:SW|Tue, 26 Feb 2008 19:36:47 GMT
vti_ct:SW|Thu, 14 Feb 2008 16:29:48 GMT
vti_cachedtitle:SR|foreign
_Author:SW|joe.smith
testcol:SR|STUFF2
After modifying the properties via the SharePoint UI the "vit_cachedcustomprops" property is updated with the custom columns. Now when I open the document in Office 2007 the property values will show up because the columns in question are in this property list. It appears that property demotion of Office 2003 files only occurs after the properties have been modified via the object model. The proof of this can be seen in two additional cases. The first case is when you upload an Office 2003 document using the SharePoint upload page. Uploading the file and not entering in any properties will result in the standard "vti_cachedcustomprops" property seen in the first example. The second case is adding an Office 2003 file via webdav and dragging it into a document library folder via Windows Explorer. So what does the object model do? If you reflect the SPListItem.Update method and follow the code path you come to an internal method PrepareItemForUpdate which is called before the AddOrUpdateItem method. Unfortunately, the PrepareItemForUpdate is obfuscated. Dead end.
I tried getting around this by creating "vti_cachedcustomprops" property and sending it with the other properties when uploading via RPC. Unfortunately, it is ignored or just overwritten.
Many companies are now complaining that Office 2003 files are broken in SharePoint 2007 when editing properties in Office 2007. I would have to agree with this assessment. Users are not aware of this "property demotion" process and open the files from SharePoint into Office 2007. They make changes to the file and never look at the properties. They then save the file back to SharePoint and all the properties are overwritten with blank values since the existing properties were not demoted. So if the user has painstakingly categorized/indexed his document so it can be found easily via SharePoint Search, then all this is blown away because of this problem, rendering this document un-retrievable in most cases. This problem could also wreak havoc on workflow, information policies, auditing and item event handlers. This is what you call a "soft data error" where data is changed with no notification, so the process of losing metadata could go for a long time before anyone is aware of the problem.
I am not sure there is a solution other than to convert your documents to Office 2007 format. The property demotion works fine with these types of documents :-) I think the problem deserves Microsoft's immediate attention.
SPSiteDataQuery limited to 10 document libraries confirmed by Microsoft
Technorati Tags: WSS SharePoint Search
In previous posts I talked about the inaccurate results received when using the SPSiteDataQuery with more than 10 document libraries or lists. http://www.sharepointblogs.com/smc750/archive/2007/07/24/spsitedataquery-limited-to-10-document-libraries-or-lists.aspx
This bug has now been confirmed with the release of KB article 946484 on January 16.
http://support.microsoft.com/kb/946484
This bug will also affect the Microsoft.SharePoint.Publishing.ContentByQueryWebPart. There seems to be no work around for this webpart because it does not have the ability to set its scope to multiple lists.
Deep Dive SharePoint 2007 Object Model
A big topic these days is about "Discoverability" and the .Net framework. Developers talk about how big the .Net framework has become with 2.0, 3.0 and now 3.5 frameworks. There a several ways to discover capabilities of a framework. One way is word of mouth via blogs or developers you work with. Another is just searching through MSDN and Google. Finally, there is the Visual Studio object browser and of course Reflector. Last year when I was developing search solutions for both WSS and MOSS I realized that the SharePoint 2007 object model had expanded and changed. This was at a time when there was little or no documentation. Even now the documentation for the SharePoint 2007 object model leaves a lot to be desired. Since SharePoint 2003 I have used a "Discovery" tool named ClassMaster (http://www.certdev.com). This tool has enabled me to dive deep into the SharePoint object model and understand how to use SharePoint to its fullest extent.
One of the biggest benefits of this tool is being able to see the object model at runtime without having to write any code. I load an assembly, enable the option to view private and internal types. I then select a method and constructor, fill in the arguments and execute. I can now see the object in an enhanced property grid which displays all the properties of the object including private and internal fields. This is useful because now I can navigate into private objects that are being used. Visual Studio's debugger does not give me this. For instance, the SPSite class has a private field for holding the SPConfigurationDatabase object. With ClassMaster I can click on the button next to this property and view all the properties for the SPConfigurationDatabase. From here I can now view the ObjectCache property of the SPConfigurationDatabase and view all the objects that are cached by SharePoint. The tool helps me see the dependencies in the object model during runtime.
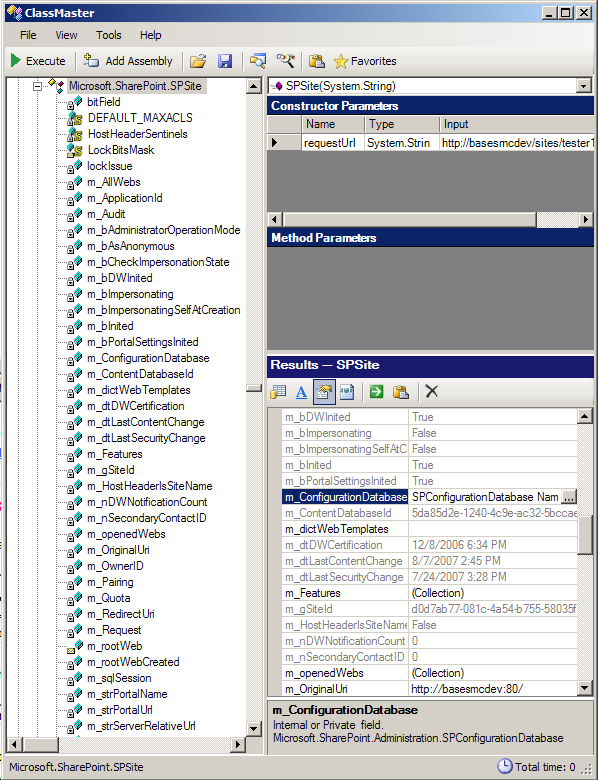
Using ClassMaster during SharePoint 2007 Development
When ever I am doing new development in SharePoint I use ClassMaster to determine if there is an existing class that I can use to perform a task. For instance, when I was trying to figure out how to obtain the start addresses that the MOSS crawler uses to crawl content. I started browsing the Microsoft.Office.Server.Search assembly. I found the StartAddressCollection. It is a public sealed class with an internal constructor that takes a ContentSource object. I right clicked on the StartAddressCollection and went directly to MSDN to see what it had to say. Of course there is nothing about the constructor since it is internal. So I looked at the ContentSource class and noticed it has a StartAddresses property. So now I know I need to create a ContentSource object to get the StartAdressCollection. However, the ContentSource object is an abstract class which means it has to be inherited. However, the ContentSource class has a "Parent" property which holds a ContentSourceCollection object.
So I navigate to ContentSourceCollection. I look at its internal constructors and see it can only be created with a Content object. Next step was to navigate to the Content class. I then see it can only be created with a SearchContext object. Looking at the SearchContext class I then discover that is has a static property called "Current" which returns the current SearchContext. I right click and execute and it returns nothing. So I right click and search MSDN. This property returns the SearchContext for the current request. Which means this only works when running in a asp.net worker process. So I look at other methods on the SearchContext class and notice the overloaded static method GetContext which takes either an SPSite, ServerContext, or a string representing the search application name. I look at the Microsoft.Office.Server.ServerContext class and see it has a static default property which returns the default ServerContext. So, from this discovery process I determined I could do this to get to the start addresses.
using Microsoft.Office.Server;
using Microsoft.Office.Server.Search.Administration;
SearchContext = Context.GetContext(ServerContext.Default);
Content con = new Content(SearchContext);
StartAddressCollection sac = con.ContentSources[0].StartAddresses;
Steps to prove this in ClassMaster
- Right click on the ServerContext.Default property and click execute.
- Save the ServerContext object to the built-in clipboard.
- Navigate to the Content class and select the constructor.
- Double click the row header in the constructor parameters grid which opens an input dialog.
- Click the clipboard icon and select the ServerContext object previously created and click OK.
- Right click the Content class and execute.
The results now show a Content object. In the property grid I could click on the ContentSources collection which brought up a ContentSource collection editor. I then selected the ContentSource I was interested in and clicked on the StartAddresses collection which displays all the Uri objects representing the start addresses that the MOSS crawler uses. Now I know what I need to code and I know it will give me exactly what I need.
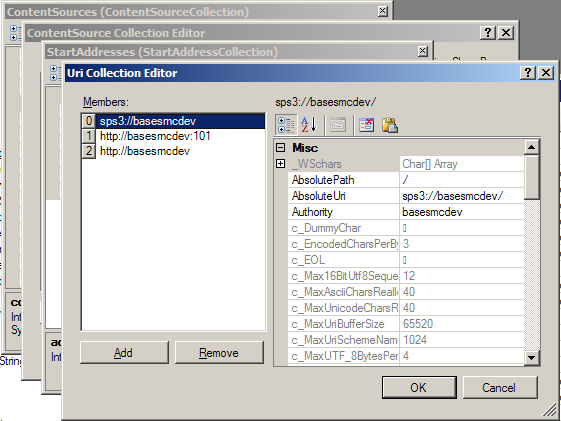
I use ClassMaster also as a unit testing tool when designing new components. I include it with my software testing regimen which includes nunit testing. It helps me see if my components are easy to develop with. Many times I have used ClassMaster for trouble shooting configuration problems on MOSS/WSS servers where the SharePoint UI does not give me enough information. Most of all I use ClassMaster because I like exploring the new functionality in SharePoint and .Net. It is very interesting to see the objects in action without having to code it all.
SPSiteDataQuery limited to 10 document libraries or lists
Technorati Tags: WSS SharePoint Search
In previous posts I talked about the pitfalls of searching in WSS or MOSS. I wanted to report one more limitation we have discovered when doing cross-list searches in WSS using the SPSiteDataQuery object. The SPWeb.GetSiteData method is used to execute cross-list searches within a site collection. This method takes a SPSiteDataQuery object which contains properties which need to be populated prior to sending it to the GetSiteData method. Using CAML (Collaborative Application Markup Language) you can construct a cross-list query. Subsets of the CAML query are then used to set the properties of the SPSiteDataQuery object, for example the Query property.
<Caml>
<Query>
<Where>
<And>
<And>
<Eq>
<FieldRef Name="InvoiceNumber"/>
<Value Type="Number">125555</Value>
</Eq>
<Eq>
<FieldRef Name="MNEMONIC"/>
<Value Type="Text">AAA</Value>
</Eq>
</And>
<Neq>
<FieldRef Name="FSObjType"/>
<Value Type="Lookup">1</Value>
</Neq>
</And>
</Where>
</Query>
<ViewFields>
<FieldRef Name="FileRef" Nullable="TRUE"/>
<FieldRef Name="EncodedAbsUrl" Nullable="TRUE"/>
<FieldRef Name="FileDirRef" Nullable="TRUE"/>
<FieldRef Name="Title" Nullable="TRUE"/>
<FieldRef Name="InvoiceNumber" Nullable="TRUE"/>
<FieldRef Name="MNEMONIC" Nullable="TRUE"/>
</ViewFields>
<QueryOptions/>
<Lists ServerTemplate="101"/>
<Webs Scope="Recursive"/>
</Caml>
This query will not return all the results if your site collection has more than 10 document libraries and any of the columns are in different order in the document libraries. This applies to lists also. Microsoft has confirmed this to be a bug. According to Microsoft when the site collection contains more than 10 document libraries the internal code escalates to use a temporary table. If document library(1).Column1 is not the same physical column as document library(2).Column1 then results are incorrect. Microsoft does not plan to fix this in SP1 but hopefully in SP2.
Workarounds?
You can make sure you limit your site collection to 10 document libraries and 10 lists. Alternatively, you can strictly control column creation within your site collections via security and the use of a well planned content type strategy (http://technet2.microsoft.com/Office/f/?en-us/library/63bb092a-00fe-45ff-a4b8-d8be998d1a3c1033.mspx). The bottom line is to not let your document library metadata columns get out of order. Finally, if you are developing on MOSS use the Microsoft.Office.Server.Search.KeywordQuery or FullTextSQLQuery classes to do your searching. If you have only a WSS 3.0 install you could use the Microsoft.SharePoint.Search.Query.KeywordQuery or FullTextSQLQuery classes. Unfortunately, you are limited to built in metadata searching and custom metadata is not supported. Ahhh, but there is a way around this which could be in a future post.
Making your SharePoint applications Information Management Policy Aware
| Office SharePoint Server 2007 shipped with a powerful new document management feature called "Information Management Policies". Information management policies can be applied to both content types and document libraries. Information management policies are a set of rules and each rule is considered a policy feature. Below is a list of available policy features in Office SharePoint Server 2007:
These policies are exposed to Office 2007 clients. For example, if a policy includes a label feature that requires that a label be inserted when saving your document to SharePoint then the user is prompted. Labels can be very useful when printing documents. Legally required metadata can be printed strategically within the document using the label feature in a policy. This post will show you how to integrate label and barcode features into your own SharePoint aware application such as PDF or TIFF document viewers using the SharePoint object model.
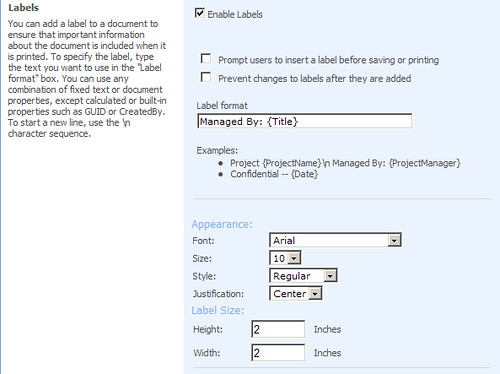
Label Policy Feature You can define a label feature for content type by defining a site collection policy from the "site collection policies" link in the site settings page of a site collection. Check the "Enable Labels" section and you can define your label. In the label format box you can type a literal value followed by a dynamic value in brackets. The dynamic value in brackets must be a name of a column within the content type you intend to associate with the label. In the appearance section you can set the font, size, style, and justification of how you want the label printed.
In order to make your applications policy aware you will have to obtain the policy for a document when you load it. This can be done via the Microsoft.Office.Policy assembly located in the GAC on the Office SharePoint 2007 server. using Microsoft.Office.RecordsManagement.InformationPolicy; using (SPSite site = new SPSite(documentUrl)) { using (SPWeb web = site.OpenWeb()) { SPFile docFile = web.GetFile(documentUrl); Policy docPolicy = Policy.GetPolicy(docFile.Item.ContentType); PolicyItem docPolicyItem = docPolicy.Items["Microsoft.Office.RecordsManagement.PolicyFeatures.PolicyLabel"]; return docPolicyItem.CustomData; }} The Policy object contains a default PolicyItemCollection containing PolicyItems. The key to the collection is a string which can be one of the following:
Note: This collection is case sensitive so it must be typed in exactly as listed above in order to get the item. Each PolicyItem's CustomData property will return a chunk of xml listing information you can use to implement SharePoint information management features. For instance, if you need information on including a label on a document before it is printed you can obtain this from the CustomData property as shown below:
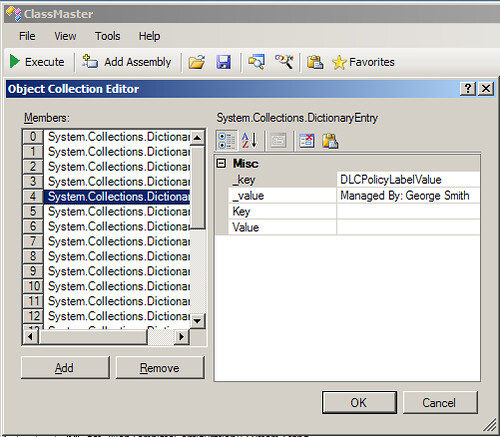
Here the policy feature calls for a label to be printed with a width of 2 inches, a height of 2 inches and an Arial font. The label will also include the literal "Managed By:" and a "metadata" segment where you are to pull the column value for Title and incorporate it into the label. You don't need to worry about the value because it can be obtained from the SPFile's DLCPolicyLabelValue property.
As you can see the value for the DLCPolicyLabelValue property has the Literal and the metadata value for "Title" merged together. This value is generated when the document is uploaded or updated in SharePoint. You now have all the information you need to add a label to the document before printing.
BarCode Policy Feature Another useful policy feature in Office SharePoint Server 2007 is BarCodes. BarCodes can be added to a document prior to printing in order to uniquely identify the document. For instance, if you upload a document into SharePoint and then print it with a barcode, then you can use the barcode value to search for the document in SharePoint. In the case of a document that needs to be printed and signed by a customer, then the document could be scanned again via a document imaging solution and automatically updated using the barcode value. You can use the same code listed above to get the xml from the CustomData property of the PolicyItem object but it will only return "<barcode/>". There is nothing in the CustomData to help you implement this policy feature. Fortunately there are three properties of the SPFile object you can use to help you implement this feature:
The _dlcBarCodeImage property contains the Base64 encoded image of the barcode that you can use to add to the document before printing. The _dlc_BarCodePreview contains a comma delimited string with the first value being a url to the preview of the image and the second value a string value with "BarCode: xxxxxxxxxx". The "xxxxxxxxxx" represents the unique 10 number that is assigned to the document when it is uploaded. The url can be used to provide a preview of the image before adding it to the document. Finally, the _dlc_BarCodeValue represents the unique 10 digit id for the document and can be used to find the document via a metadata search when scanning the document back into SharePoint. Note: Please beware that after you have associated a policy with a content type and then make changes to the policy, the changes will not be reflected within the contentType until you un-associate and re-associate the policy with the content type. In addition, the label value will only be updated after policy changes if the item is updated. Information Management Policy is new to SharePoint but not to the world of Document Management. Office SharePoint Server 2007 has added many new Document Management capabilities your applications can take advantage of.
|
{kind=link}
{kind=link}
Subscribe to:
Comments (Atom)